The Currency of the Machine
Tokens are how the machine reads, how the vendors charge, and why the meter is worth understanding before the bill arrives.
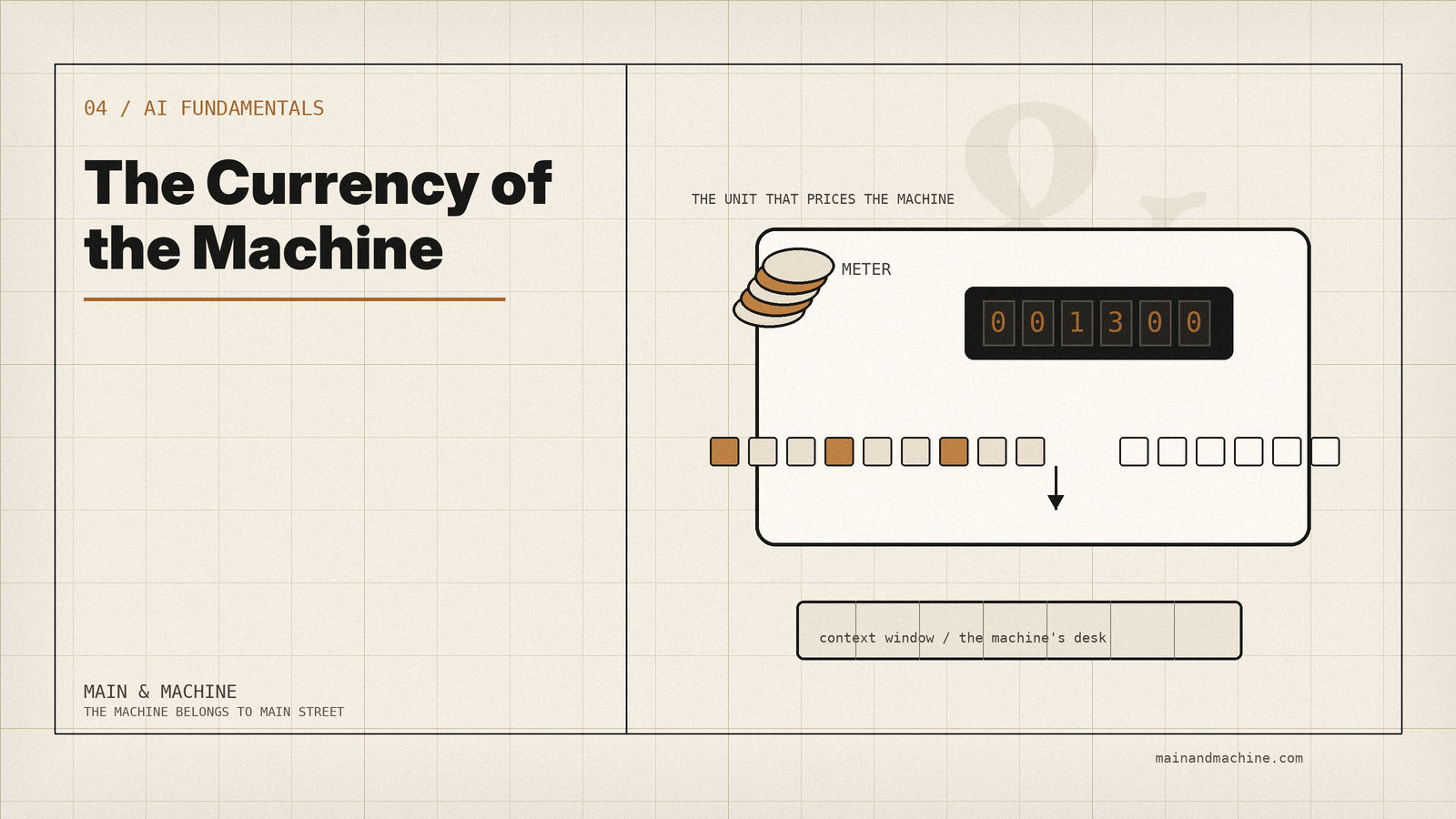
Every AI invoice in the world is denominated in a unit most of the people paying it have never examined.
The unit is the token, and it sounds like trivia until you realize it sets the price of every automated email, decides how much of your handbook the machine can hold in mind at once, and explains why the chatbot seemed to forget the beginning of a long conversation. Owners learn the vocabulary of their costs in every other corner of the business: board feet, billable hours, food cost percentage. This one takes ten minutes and pays for itself.
How the Machine Reads
A language model does not see words, exactly. Before your text reaches the model, it is chopped into tokens: common words usually survive as single pieces, longer or rarer words get split into fragments, and punctuation takes its own slots. In English, a useful rule of thumb is that a token is about three-quarters of a word, so a thousand words of text runs roughly thirteen hundred tokens. The model reads tokens in, and it writes tokens out, one at a time, each one chosen by the prediction process described earlier in this series.
Two business-relevant facts hang off this detail.
The first is pricing. The major providers charge by the token, typically quoted per million, with separate rates for tokens in and tokens out, and with the largest models costing many multiples of the small ones. The meter runs on volume both directions. Feed the machine a three-hundred-page document and you pay for every page whether it needed all of them or only the table on page twelve. Ask for a one-paragraph answer instead of a five-page one and the output side of the meter barely moves.
The second is memory. Every model has a context window: the maximum number of tokens it can consider at once, covering your instructions, your documents, the conversation so far, and its own reply. Think of it as the machine’s desk. Modern desks are enormous, hundreds of thousands of tokens on the frontier models, room for several novels. But the desk is finite, and when a conversation outgrows it, the earliest material slides off the edge. The machine has no shelf behind the desk. What is off the desk is gone, which is why the chatbot that was brilliant for an hour suddenly cannot remember the constraint you established at the start.
The Telegraph Rule
There is a historical rhyme here that I find clarifying. When the telegraph priced messages by the word, it changed how people wrote. Victorian businessmen developed a clipped, compressed cable style, codebooks turned whole sentences into single words, and an entire generation learned that precision was cheaper than rambling. The constraint shaped the communication.
Token pricing is the cable rate of this era, and it should shape your habits the same gentle way. The skill is curation. The owner who pastes the entire customer file gets a worse answer at a higher price than the one who pastes the three relevant pages, because the model’s attention, like anyone’s, dilutes across a cluttered desk. Sending less, better-chosen material is simultaneously the cost optimization and the quality optimization. That alignment is rare in business, and worth exploiting.
Some of you are running the other direction with this, and I want to head it off: the meter should worry you less than you think. Per-token prices have fallen relentlessly as competition and efficiency improve, and for a typical small business using these tools through a chat interface or a modest automation, the monthly model bill is lunch money next to the labor hours in play. A workflow that drafts two hundred customer replies might cost less in tokens than a single hour of the employee time it saves. The meter matters when you build automations that run thousands of times, when you routinely process enormous documents, or when a vendor’s pricing quietly passes token costs through to you at a markup. Which is to say: the meter matters at exactly the moments when you are signing something.
Reading the Meter Like an Owner
The practical residue of all this fits in a few habits. Match the model to the task, because the small, cheap models handle routine summarization and classification gracefully, and the expensive frontier models earn their rate on the genuinely hard work. Trim what you feed in, for quality as much as cost. Expect long conversations to degrade, and start fresh ones for new tasks instead of piling everything onto one endless thread. And when a vendor quotes you a per-seat or per-task price for an AI feature, ask what the underlying token economics look like, the same way you would ask a contractor about materials. The ones who can answer crisply tend to be the ones who built something real.
The token is a small idea, but small ideas about units have a way of compounding. The owner who knows what a board foot costs builds differently from the one who does not. Same lumber, different margins.
Where this shows upWhat AI costs to run, monthly →